나이브 베이즈 분류의 기본 (Basics of Naive Bayes Classification) - NBC
arkainoh
일요일, 7월 08, 2018
1. 개요
나이브 베이즈 분류(Naive Bayes Classification, 이하 NBC)는 가장 기본적이면서 자주 쓰이는 매우 유용한 분류 방법이다. 예제와 함께 나이브 베이즈 분류의 개념과 특징을 알아보고, 한계와 극복 방안, 그리고 활용 사례에 대해 살펴보도록 하겠다.
2. NBC의 기본 가정 및 방법
NBC의 기본적인 가정은, 어떤 객체의 속성들이 서로 독립적이라는 것이다. 예를 들어, 분류해야 할 객체 x의 정보가 벡터로 주어진다면, 각 벡터의 요소들은 x의 속성들이라고 할 수 있으며 이들은 모두 독립적이다. 쉽게 말해서, 인간이라는 객체의 속성을 키와 몸무게라고 가정했을 경우 키와 몸무게가 상호 독립적이라고 가정하는 것이다.
이러한 가정에 의해, x가 주어졌을 때 특정 클래스 Ck로 분류하는 NBC는 다음과 같이 진행할 수 있다.
 즉, P(x1x2x3...xn | Ck)를 P(xi | Ck)들의 곱이라고 생각한다. 각 요소들의 Class Likelihood를 전부 곱해버리는 것이다. 우선, NBC를 진행하기 전 학습 과정을 의사 코드(Pseudocode)로 나타내면 다음과 같다.
즉, P(x1x2x3...xn | Ck)를 P(xi | Ck)들의 곱이라고 생각한다. 각 요소들의 Class Likelihood를 전부 곱해버리는 것이다. 우선, NBC를 진행하기 전 학습 과정을 의사 코드(Pseudocode)로 나타내면 다음과 같다.
 이때 r은 One-hot Encoded Vector이다. 예를 들어, 주어진 데이터 x가 두 번째 클래스(C2)에 속한다는 것을 나타내는 r은 [0 1 0]이다. 따라서, 이 정보를 활용하여 데이터 D가 주어졌을 때, 우선 각 클래스마다 데이터가 몇 개 속해있는지 카운트하여 (1)의 Priority Probability를 구한다. 그 다음, 각 클래스별로 (2)의 Class Likelihood를 구해놓으면 학습이 끝난다.
이때 r은 One-hot Encoded Vector이다. 예를 들어, 주어진 데이터 x가 두 번째 클래스(C2)에 속한다는 것을 나타내는 r은 [0 1 0]이다. 따라서, 이 정보를 활용하여 데이터 D가 주어졌을 때, 우선 각 클래스마다 데이터가 몇 개 속해있는지 카운트하여 (1)의 Priority Probability를 구한다. 그 다음, 각 클래스별로 (2)의 Class Likelihood를 구해놓으면 학습이 끝난다.
예시와 함께 살펴보도록 하자. 객체 x는 [키, 몸무게]로 이루어진 벡터로 주어지고, 클래스는 남자 혹은 여자로 주어진다고 가정하자.
 그렇다면, D를 구성하는 데이터들은 다음과 같이 주어질 것이다.
그렇다면, D를 구성하는 데이터들은 다음과 같이 주어질 것이다.
 이 정보들을 종합하여 위 코드에서 (1)의 Priority Probability를 먼저 구해보자. 데이터들을 카운트하여 표에 정리했더니 다음과 같이 결과가 나타났다고 생각해보자.
이 정보들을 종합하여 위 코드에서 (1)의 Priority Probability를 먼저 구해보자. 데이터들을 카운트하여 표에 정리했더니 다음과 같이 결과가 나타났다고 생각해보자.
 그렇다면 전체 데이터 개수 N은 10이기 때문에, P(C1) = 4 / 10 = 0.4이고, P(C2) = 6 / 10 = 0.6이라는 사실을 쉽게 알 수 있다. 다음은 (2)의 Class Likelihood를 구해보자. 각 클래스별로, 그리고 각 속성별로 진행을 하면서, 특정 클래스에 속한 데이터 중에서 특정 속성 값을 가진 데이터가 몇 개 있는지 카운트하여 표에 정리한다.
그렇다면 전체 데이터 개수 N은 10이기 때문에, P(C1) = 4 / 10 = 0.4이고, P(C2) = 6 / 10 = 0.6이라는 사실을 쉽게 알 수 있다. 다음은 (2)의 Class Likelihood를 구해보자. 각 클래스별로, 그리고 각 속성별로 진행을 하면서, 특정 클래스에 속한 데이터 중에서 특정 속성 값을 가진 데이터가 몇 개 있는지 카운트하여 표에 정리한다.
 (1)과 (2)를 모두 구하였기 때문에, 분류를 위한 학습이 완료되었다. 그렇다면, 이렇게 학습된 정보를 바탕으로 키가 170, 몸무게가 50인 x가 남자인지 여자인지 분류해보자.
(1)과 (2)를 모두 구하였기 때문에, 분류를 위한 학습이 완료되었다. 그렇다면, 이렇게 학습된 정보를 바탕으로 키가 170, 몸무게가 50인 x가 남자인지 여자인지 분류해보자.
 P(C1 | x)와 P(C2 | x)를 구했을 때, P(C2 | x)가 1 / 20으로 더욱 큰 값을 가지므로, x는 C2, 즉, 남자로 분류된다.
P(C1 | x)와 P(C2 | x)를 구했을 때, P(C2 | x)가 1 / 20으로 더욱 큰 값을 가지므로, x는 C2, 즉, 남자로 분류된다.
3. NBC의 한계와 극복 방안
NBC는 매우 간단하고 실제 많은 분류 문제에서 강력한 성능을 발휘한다. 단, 문제점이 몇 가지 존재한다. 대표적으로 세 가지 정도를 생각해 볼 수 있는데, 각각에 대해 차근차근 알아보도록 하자.
(1) 실수 데이터의 처리
첫 번째 문제는 데이터의 범위와 관련된 문제이다. 예를 들어, 2의 예제에서 키가 정수가 아닌 실수형으로 주어진다고 생각해보자. 위의 예시에서는 정수형으로 주어졌기 때문에 키가 160인 사람이 몇 명인지 셀 수 있었지만, 키가 170.1, 170.232... 이런식으로 실수로 주어진다면 Class Likelihood를 제대로 구할 수 없다. P(x = v | Ck)가 전부 1 / Ck가 될 것이기 때문이다. 따라서 학습이 제대로 되지 않는다. 또한 분류도 문제이다. 학습 중에는 키가 170.3인 데이터가 없었는데 이 데이터를 분류해야 할 경우, 170.3에 대한 Class Likelihood를 구할 수 없으므로 분류가 제대로 되지 않는다.
이 문제는 완벽하게 해결할 수 없지만, 임시 방편으로 데이터를 정수 구간별로 묶는 방법을 사용할 수 있다. 예를 들어, 10 단위로 몸무게, 키를 묶어서 생각하는 것이다. 이 경우, 170.1, 170.2, 170.3의 키를 가진 각각의 데이터가 존재할 때, 키 170 ~ 180 범위의 데이터가 3개 존재한다고 생각할 수 있게 된다. 또한, 170.4의 키를 가진 데이터가 분류되어야 할 때, 이 데이터가 170 ~ 180 범위에 속한다는 가정 때문에 정상적으로 분류가 가능하게 된다.
(2) 빈번한 0
두 번째 문제는 학습과 분류 과정에서, 확률을 계산한 결과가 0이 나오는 경우가 너무 빈번하다는 것이다. 모든 속성에 대한 Class Likelihood를 곱한다는 특징때문에, 한 속성이라도 Class Likelihood가 0이 되는 경우 결과 확률이 무조건 0이 된다는 문제점이 있다. 2의 예제에서도 볼 수 있듯이, Class Likelihood가 0인 경우가 쉽게 나타난다. 학습 과정에서 특정 속성 값을 가진 데이터가 하나도 없는 경우, 해당 속성 값에 대한 Class Likelihood가 0이 되어 다른 속성 값들을 무의미하게 만들어버린다.
이를 해결하기 위한 방법 중의 하나로, 일종의 가중치, 혹은 편향(Bias)을 확률에 더해주는 방법이 있다.
 b의 값은 데이터의 분포를 보고 적절한 값을 선택하면 된다. b의 값이 클수록 Prior Probability를 더욱 신뢰하는 효과가 있다.
b의 값은 데이터의 분포를 보고 적절한 값을 선택하면 된다. b의 값이 클수록 Prior Probability를 더욱 신뢰하는 효과가 있다.
(3) 종속성
세 번째 문제는 NBC의 근본적인 문제라고 할 수 있다. 바로 종속성과 관련된 문제이다. NBC에서는 모든 특정 객체의 속성들이 모두 독립적이라고 보기 때문에, 종속성이 있는 속성이 주어질 경우 문제가 발생할 수 있다. 2의 예제에서만 봐도, 키와 몸무게는 종속성이 있다고 생각할 수 있다. 키와 몸무게는 비례하기 마련이다. 하지만, NBC에서는 키와 몸무게가 철저히 독립적이라고 가정한다. 따라서 종속성이 매우 높은 속성들을 가진 데이터가 주어지는 문제의 경우 바람직한 결과를 기대할 수 없다. 이러한 경우, NBC에서는 딱히 해결 방법이 없다. NBC 외에 다른 분류 방법을 고려해봐야 한다.
4. NBC의 활용 사례
NBC를 실제 어떤 Application에 적용할 수 있을까? 대표적인 예로 가장 유명한 스팸(Spam) 메일 분류기가 있다. C1 = Spam, C2 = Ham이라고 가정한 뒤, 이메일 x가 주어졌을 때 이를 Spam 혹은 Ham으로 분류하는 것이다. x는 Bag Of Words 벡터로 주어진다. 이메일에 등장할 수 있는 단어의 종류를 모두 구해서 Dictionary로 만들고, x가 Dictionary의 단어 중 n 번째에 위치한 단어를 가지고 있으면 1, 그렇지 않으면 0로 인코딩하여 x를 0과 1로 이루어진 벡터로 만드는 것이다. 예를 들어, 이메일에 등장할 수 있는 단어의 수가 4개(Dictionary의 크기 = 4)이고 이메일 x에서 두 번째, 세 번째 단어가 나타났다면, x = [0 1 1 0]으로 나타낸다. 이를 바탕으로 Prior Probability와 단어 별로 Class Likelihood들을 구하여 학습을 하면, 강력한 스팸 분류기가 탄생한다. 실제로, 여러 이메일 시스템에서 이렇게 NBC를 활용한 스팸 처리기를 활용해왔다고 한다.
5. 정리
NBC는 데이터의 속성들이 모두 독립적이라는 가정 하에, 각 속성의 Class Likelihood를 전부 곱해버리는 방법이다. 따라서 Multivariate 문제를 Univariate 문제로 축소하여 해결한다는 특징이 있다. 학습은 Maximum Likelihood Estimation(MLE)을 활용하여 진행하고, 분류는 Maximum a Posteriori Estimation(MAP)을 활용하여 진행한다.
이 글에서는 데이터가 이산 확률 분포를 따른다는 가정이었지만, 이후의 글에서는 데이터가 연속확률분포를 따를 경우에 이 특성을 활용해 NBC로 파라미터 학습(Parametric Learning)을 진행하는 방법에 대해 살펴보도록 하겠다.
6. References
Alpaydın, Ethem. Introduction to machine learning. Cambridge, MA: MIT Press, 2014. Print.
나이브 베이즈 분류(Naive Bayes Classification, 이하 NBC)는 가장 기본적이면서 자주 쓰이는 매우 유용한 분류 방법이다. 예제와 함께 나이브 베이즈 분류의 개념과 특징을 알아보고, 한계와 극복 방안, 그리고 활용 사례에 대해 살펴보도록 하겠다.
2. NBC의 기본 가정 및 방법
NBC의 기본적인 가정은, 어떤 객체의 속성들이 서로 독립적이라는 것이다. 예를 들어, 분류해야 할 객체 x의 정보가 벡터로 주어진다면, 각 벡터의 요소들은 x의 속성들이라고 할 수 있으며 이들은 모두 독립적이다. 쉽게 말해서, 인간이라는 객체의 속성을 키와 몸무게라고 가정했을 경우 키와 몸무게가 상호 독립적이라고 가정하는 것이다.
이러한 가정에 의해, x가 주어졌을 때 특정 클래스 Ck로 분류하는 NBC는 다음과 같이 진행할 수 있다.
예시와 함께 살펴보도록 하자. 객체 x는 [키, 몸무게]로 이루어진 벡터로 주어지고, 클래스는 남자 혹은 여자로 주어진다고 가정하자.
3. NBC의 한계와 극복 방안
NBC는 매우 간단하고 실제 많은 분류 문제에서 강력한 성능을 발휘한다. 단, 문제점이 몇 가지 존재한다. 대표적으로 세 가지 정도를 생각해 볼 수 있는데, 각각에 대해 차근차근 알아보도록 하자.
(1) 실수 데이터의 처리
첫 번째 문제는 데이터의 범위와 관련된 문제이다. 예를 들어, 2의 예제에서 키가 정수가 아닌 실수형으로 주어진다고 생각해보자. 위의 예시에서는 정수형으로 주어졌기 때문에 키가 160인 사람이 몇 명인지 셀 수 있었지만, 키가 170.1, 170.232... 이런식으로 실수로 주어진다면 Class Likelihood를 제대로 구할 수 없다. P(x = v | Ck)가 전부 1 / Ck가 될 것이기 때문이다. 따라서 학습이 제대로 되지 않는다. 또한 분류도 문제이다. 학습 중에는 키가 170.3인 데이터가 없었는데 이 데이터를 분류해야 할 경우, 170.3에 대한 Class Likelihood를 구할 수 없으므로 분류가 제대로 되지 않는다.
이 문제는 완벽하게 해결할 수 없지만, 임시 방편으로 데이터를 정수 구간별로 묶는 방법을 사용할 수 있다. 예를 들어, 10 단위로 몸무게, 키를 묶어서 생각하는 것이다. 이 경우, 170.1, 170.2, 170.3의 키를 가진 각각의 데이터가 존재할 때, 키 170 ~ 180 범위의 데이터가 3개 존재한다고 생각할 수 있게 된다. 또한, 170.4의 키를 가진 데이터가 분류되어야 할 때, 이 데이터가 170 ~ 180 범위에 속한다는 가정 때문에 정상적으로 분류가 가능하게 된다.
(2) 빈번한 0
두 번째 문제는 학습과 분류 과정에서, 확률을 계산한 결과가 0이 나오는 경우가 너무 빈번하다는 것이다. 모든 속성에 대한 Class Likelihood를 곱한다는 특징때문에, 한 속성이라도 Class Likelihood가 0이 되는 경우 결과 확률이 무조건 0이 된다는 문제점이 있다. 2의 예제에서도 볼 수 있듯이, Class Likelihood가 0인 경우가 쉽게 나타난다. 학습 과정에서 특정 속성 값을 가진 데이터가 하나도 없는 경우, 해당 속성 값에 대한 Class Likelihood가 0이 되어 다른 속성 값들을 무의미하게 만들어버린다.
이를 해결하기 위한 방법 중의 하나로, 일종의 가중치, 혹은 편향(Bias)을 확률에 더해주는 방법이 있다.
(3) 종속성
세 번째 문제는 NBC의 근본적인 문제라고 할 수 있다. 바로 종속성과 관련된 문제이다. NBC에서는 모든 특정 객체의 속성들이 모두 독립적이라고 보기 때문에, 종속성이 있는 속성이 주어질 경우 문제가 발생할 수 있다. 2의 예제에서만 봐도, 키와 몸무게는 종속성이 있다고 생각할 수 있다. 키와 몸무게는 비례하기 마련이다. 하지만, NBC에서는 키와 몸무게가 철저히 독립적이라고 가정한다. 따라서 종속성이 매우 높은 속성들을 가진 데이터가 주어지는 문제의 경우 바람직한 결과를 기대할 수 없다. 이러한 경우, NBC에서는 딱히 해결 방법이 없다. NBC 외에 다른 분류 방법을 고려해봐야 한다.
4. NBC의 활용 사례
NBC를 실제 어떤 Application에 적용할 수 있을까? 대표적인 예로 가장 유명한 스팸(Spam) 메일 분류기가 있다. C1 = Spam, C2 = Ham이라고 가정한 뒤, 이메일 x가 주어졌을 때 이를 Spam 혹은 Ham으로 분류하는 것이다. x는 Bag Of Words 벡터로 주어진다. 이메일에 등장할 수 있는 단어의 종류를 모두 구해서 Dictionary로 만들고, x가 Dictionary의 단어 중 n 번째에 위치한 단어를 가지고 있으면 1, 그렇지 않으면 0로 인코딩하여 x를 0과 1로 이루어진 벡터로 만드는 것이다. 예를 들어, 이메일에 등장할 수 있는 단어의 수가 4개(Dictionary의 크기 = 4)이고 이메일 x에서 두 번째, 세 번째 단어가 나타났다면, x = [0 1 1 0]으로 나타낸다. 이를 바탕으로 Prior Probability와 단어 별로 Class Likelihood들을 구하여 학습을 하면, 강력한 스팸 분류기가 탄생한다. 실제로, 여러 이메일 시스템에서 이렇게 NBC를 활용한 스팸 처리기를 활용해왔다고 한다.
5. 정리
NBC는 데이터의 속성들이 모두 독립적이라는 가정 하에, 각 속성의 Class Likelihood를 전부 곱해버리는 방법이다. 따라서 Multivariate 문제를 Univariate 문제로 축소하여 해결한다는 특징이 있다. 학습은 Maximum Likelihood Estimation(MLE)을 활용하여 진행하고, 분류는 Maximum a Posteriori Estimation(MAP)을 활용하여 진행한다.
이 글에서는 데이터가 이산 확률 분포를 따른다는 가정이었지만, 이후의 글에서는 데이터가 연속확률분포를 따를 경우에 이 특성을 활용해 NBC로 파라미터 학습(Parametric Learning)을 진행하는 방법에 대해 살펴보도록 하겠다.
6. References
Alpaydın, Ethem. Introduction to machine learning. Cambridge, MA: MIT Press, 2014. Print.




















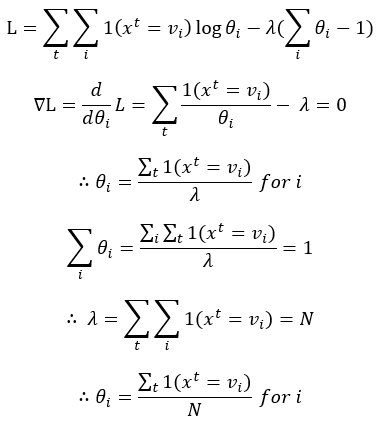







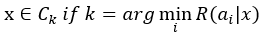




![[C/C++] 고정 소수점의 모든 것 (All about Fixed Point)](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjIsNbQ5x9v-Z-WFogOWc-Lns6r9bJLAy9DBCVnl33dXsyXViNgjXrSvmnXzfOeL8m5Wb5VqImEKI0L-B9ZXzc2XmgWpmKCVFv87svXDsHG5WO_4sqVg-y2sRtuqbStxGf2HQ28wBdKIKBV/w72-h72-p-k-no-nu/%25EA%25B3%25A0%25EC%25A0%2595+%25EC%2586%258C%25EC%2588%2598%25EC%25A0%2590+%25EA%25B7%25B8%25EB%25A6%25BC.PNG)


![[R] 다중 회귀 분석 (Multiple Regression Analysis)](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEgcv_-dAHO3EpXA84aAoidUMHJU6rKRsfYflGImKb829FBTDDyw01WftJ-PZD_UakTKM4u5KeubMIaau5zkwBtuYXPqdkpbvFOI_Tv3FFjKFYxkCaKknGFyclAUQrJlzyGwOtLzvotXhTFT/w72-h72-p-k-no-nu/%25ED%259A%258C%25EA%25B7%2580+%25EB%25B6%2584%25EC%2584%259D.PNG)
