Streaming 1: 스트리밍의 정의와 관련 용어 및 개념 정리
arkainoh
일요일, 10월 28, 2018
1. 개요
빅 데이터 시대에 스트리밍은 매우 중요한 화제로 대두되고 있다. 수많은 IoT 기기의 센서들로부터 쏟아지는 데이터, Youtube와 같이 인터넷에서 실시간으로 제공되는 동영상 스트리밍 서비스, 혹은 Melon, Genie와 같은 음악 스트리밍 서비스 등 스트리밍을 활용하는 사례는 점점 더 많아지고 있다. 이 글은 스트리밍에 대한 깊은 이해와 구현을 목표로 하며, 시리즈로 진행할 예정이다. Streaming 시리즈에 포함된 모든 글은 The world beyond batch: Streaming 101과 The world beyond batch: Streaming 102의 내용을 토대로 번역 및 요약정리를 한 결과이다.
2. 스트리밍(Streaming)이란?
스트리밍이라는 용어는 다양한 의미로 사용된다. 이 글에서는 무한히 흘러들어오는 데이터를 지속적으로 처리해주는 데이터 처리 엔진의 일종으로 정의한다. 엄밀히 말하면, 일반적인 스트리밍뿐만 아니라, 마이크로 배치(Micro-Batch)를 사용하는 것까지 포함할 수 있다. 이에 대한 자세한 내용은 곧 데이터의 종류에 대한 설명과 함께 이어가도록 하겠다.
스트리밍은 무한한 규모의 데이터를 처리할 때 주로 사용되며, 데이터가 도착하는 대로 처리한다는 특징 때문에 다양한 장점이 있다. 대표적으로 짧은 응답시간이 있다. 그리고 지속적으로 흘러들어오는 데이터의 양이 일정하다고 가정한다면, 데이터를 처리하기 위한 하드웨어 자원의 소모가 예측 가능하고, 따라서 워크로드를 적절히 분배하기 쉽다는 이점이 있다.
2.1 Unbounded data
계속 무한히 증가하는 데이터, 흔히 스트리밍 데이터라고 여겨진다. 그런데, 스트리밍, 혹은 배치(Batch)라는 용어는 특정 데이터를 처리할 때 사용되는 엔진과 관련이 있기 때문에, 조심스럽게 사용해야 한다. 따라서, 이 글에서는 데이터의 종류를 유한성으로 구분하도록 한다. 즉, 무한한 것은 Unbounded data, 유한한 것은 Bounded data라고 정의한다. 우선은 무한한 스트리밍 데이터를 Unbounded data, 유한한 배치 데이터를 Bounded data라고 쉽게 대입해서 생각해도 좋다.
2.2 Unbounded data processing
무한히 흘러드는 Unbounded data를 실시간으로, 그리고 지속적으로 처리하는 방식이다. 일반적인 의미의 스트리밍 엔진뿐만 아니라, 배치 엔진을 반복적으로 사용하는 것도 Unbounded data processing이 될 수 있다. 따라서, 이 글에서 이하 "스트리밍"이라는 용어의 사용은 단순히 Unbounded data를 처리하기 위한 엔진을 의미한다고 가정한다.
3. 스트리밍에 대한 오해 및 새로운 가능성
스트리밍 시스템이 할 수 있는 것과 할 수 없는 것에 대해서 살펴보도록 하자. 이 글의 목적은 잘 디자인된 스트리밍 시스템이 어떤 긍정적인 모습으로 나타날 수 있는지를 강조하는 것이기 때문에, 스트리밍 시스템이 잘 할 수 있는 것들에 중점을 두고 설명을 진행하도록 하겠다.
3.1 Lambda architecture
스트리밍 시스템은 오랜 기간에 걸쳐 부정확하고, 추측에 근거한 결과들을 내놓는다는 부정적인 시선에 시달려왔다. 이러한 선입견은 Lambda Architecture와 같이 상대적으로 정확한 결과들을 도출해내는 배치 시스템들에 의해 더욱 부각되었다. Lambda Architecture의 기본 아이디어는 같은 연산을 수행하는 스트리밍 시스템과 배치 시스템을 함께 사용하는 것이다. 일반적으로, 스트리밍 시스템에서 자주 사용되는 Approximation 알고리즘을 적용하거나, 혹은 스트리밍 시스템 자체가 결과의 정확성에 대한 보장을 해주지 않는 경우 때문에 부정확한 결과가 도출될 수도 있다. 따라서, 이후에 배치 시스템이 따라 실행되면서 정확한 결과를 얻어낼 수 있도록 일조하는 것이다.
결과적으로, 이 아이디어는 굉장히 성공적이었다. 그도 그럴 것이, 스트리밍 엔진은 정확성 측면에서는 부족한 점이 많기 때문이다. 하지만, 람다 시스템은 큰 약점을 가지고 있다. 람다 시스템의 관리자는 두 개의 독립적인 버전의 시스템을 따로 빌드하고 배포해야 하며, 결과적으로 두 개의 파이프라인의 결과를 병합해야 하는 등, 유지보수에 두 배의 노력이 필요하다.
Jay Krep은 이 람다 시스템에 의문을 제기하며, Questioning the Lambda Architecture와 같은 게시글에서 반복성과 관련된 가능성을 제시한다. Kafka처럼 재사용성을 제공하는 스트리밍 상호연결체를 바탕으로 한 시스템을 사용하는, 다시 말해서, 특정 작업을 수행하기 위한 목적으로 잘 디자인된 한 가지 파이프라인을 사용하는 Kappa Architecture를 제안한다.
이 아이디어에 더해 첨언하자면, 사실상 잘 디자인된 스트리밍 시스템은 이론적으로 배치 시스템의 기능적인 상위호환이 될 수 있다고 생각한다. 스트리밍 시스템으로 배치 시스템을 이기려면, 정확성과 시간에 대한 추론이라는 두 마리 토끼를 잡아야 한다.
3.2 Correctness
스트리밍 시스템이 정확성을 갖게 된다면, 배치 시스템과 동등한 지위를 얻게 된다. 정확성 보장의 핵심은 일관된 스토리지 저장소에 있다. 스트리밍 시스템은 전체 시간의 흐름 속에서 끊임 없는 상태(State)의 변화를 기록(Checkpointing)해둘 수 있는 방법이 필요하다. (참고: Jay Krep's Why local state is a fundamental primitive in stream processing) 그리고 시스템 장애와 관련된 측면에서도 시스템의 일관성을 충분히 유지할 수 있도록 잘 디자인되어야 한다. 적어도 정확히 한 번의 처리에 있어서, 강력한 일관성을 보장하는 것이 배치 시스템과의 경쟁에서 승리할 수 있는 토대이다. 처음 Spark 스트리밍이 처음 빅 데이터 필드에 출현했을 때, 이러한 일관성을 보장하도록 스트리밍 시스템들을 인도하는 등대같은 존재가 되었다. 다행스럽게도 이후에 비약적인 발전이 이루어졌다.
3.3 Tools for reasoning about time
스트리밍 시스템에 시간에 대한 추론을 할 수 있는 도구까지 제공된다면, 배치 시스템을 앞서게 된다. 시간상 순차적으로 발생하는 Unbounded data가 네트워크 지연으로 인해 시스템에 전송되면서 순서가 뒤죽박죽이 되기 때문에, 실제 데이터의 발생 시간을 추론해주는 도구는 필수적이다. 이에 대한 심층적인 이해에 앞서, 시간 도메인(Time domains)과 관련된 핵심적인 개념들을 짚고 넘어가도록 하겠다.
4. Event time vs Processing time
이 글에서 사용할 시간 관련 용어로는 Event time과 Processing time이 있다. 이 둘의 정의는 다음과 같다.
 검은색 점선으로 표시된 대각선이 이상적인 경우이고, 빨간색 곡선이 현실을 반영한 것이다. 그리고 Event time과 Processing time 사이에 발생하는 수평 방향의 격차가 Skew이다. 이 Skew는 데이터를 처리하는 파이프라인으로 인해 발생하는 지연이라고 할 수 있다.
검은색 점선으로 표시된 대각선이 이상적인 경우이고, 빨간색 곡선이 현실을 반영한 것이다. 그리고 Event time과 Processing time 사이에 발생하는 수평 방향의 격차가 Skew이다. 이 Skew는 데이터를 처리하는 파이프라인으로 인해 발생하는 지연이라고 할 수 있다.
Event time과 Processing time을 매핑하는 것은 정적이지 않기 때문에, 데이터가 실제 발생한 시간이나 순서를 고려해야 하는 경우, 데이터를 분석하는 것은 매우 어려운 작업이 된다. 이러한 문제를 극복하고 무한히 흘러들어오는 Unbounded data를 잘 처리하기 위해서 Windowing과 같은 기법들을 사용하곤 한다. Windowing에 대한 자세한 내용은 다음 글에서 다루도록 하겠다. Windowing의 기본 아이디어는 데이터를 시간상에서 유한한 작은 조각들로 나누어 처리한다는 것이다.
만약 정확성이 요구되는 상황이거나 시계열 데이터를 처리하는 경우, Processing time을 기준으로 Windowing을 하면 문제가 발생한다. Event time과 Processing time의 관계를 정밀하게 분석하여 Event time을 기준으로 Windowing을 해야 한다. 이 과정에서 같은 Window에서 처리되어야 할 Event time 기반의 데이터가 다른 Window에 배정되는 경우 등 여러가지 예외상황들을 함께 고려해주면 된다.
하지만 불행하게도, Event time을 기준으로 Windowing을 하는 것도 마냥 장밋빛 미래를 선사하지는 않는다. Unbounded data를 처리한다는 맥락에서는, 데이터의 무질서와 일관되지 않은 Skew로 인해, 즉, Event time과 Processing time의 완벽한 매핑의 부재로 인해, 특정 Event time X에서 발생한 모든 데이터가 특정 Processing time에 관찰되었다는 식으로 단정짓기가 힘들다. 이를 Completeness의 문제라고 정의한다.
단순히 Unbounded data를 유한한 배치들로 나누어서 결과적으로 Completeness를 보장하는 식의 접근보다는, 복잡한 데이터로 인해 발생하는 불확실성에 대응할 수 있는 도구들을 디자인하는 접근 방식이 요구된다. Completeness의 관점에서 볼 때, 바람직한 시스템은 새로운 데이터가 들어올 경우, 오래된 데이터를 철회하거나 갱신하는 과정을 스스로 수행할 수 있어야 한다. 이러한 시스템에 대해 상세히 논의하기 전 이론적인 초석을 다지기 위하여, 다음 글에서는 데이터를 처리하는 여러가지 기법들에 대해서 자세히 살펴보도록 하겠다.
5. References
https://www.oreilly.com/ideas/the-world-beyond-batch-streaming-101
빅 데이터 시대에 스트리밍은 매우 중요한 화제로 대두되고 있다. 수많은 IoT 기기의 센서들로부터 쏟아지는 데이터, Youtube와 같이 인터넷에서 실시간으로 제공되는 동영상 스트리밍 서비스, 혹은 Melon, Genie와 같은 음악 스트리밍 서비스 등 스트리밍을 활용하는 사례는 점점 더 많아지고 있다. 이 글은 스트리밍에 대한 깊은 이해와 구현을 목표로 하며, 시리즈로 진행할 예정이다. Streaming 시리즈에 포함된 모든 글은 The world beyond batch: Streaming 101과 The world beyond batch: Streaming 102의 내용을 토대로 번역 및 요약정리를 한 결과이다.
2. 스트리밍(Streaming)이란?
스트리밍이라는 용어는 다양한 의미로 사용된다. 이 글에서는 무한히 흘러들어오는 데이터를 지속적으로 처리해주는 데이터 처리 엔진의 일종으로 정의한다. 엄밀히 말하면, 일반적인 스트리밍뿐만 아니라, 마이크로 배치(Micro-Batch)를 사용하는 것까지 포함할 수 있다. 이에 대한 자세한 내용은 곧 데이터의 종류에 대한 설명과 함께 이어가도록 하겠다.
스트리밍은 무한한 규모의 데이터를 처리할 때 주로 사용되며, 데이터가 도착하는 대로 처리한다는 특징 때문에 다양한 장점이 있다. 대표적으로 짧은 응답시간이 있다. 그리고 지속적으로 흘러들어오는 데이터의 양이 일정하다고 가정한다면, 데이터를 처리하기 위한 하드웨어 자원의 소모가 예측 가능하고, 따라서 워크로드를 적절히 분배하기 쉽다는 이점이 있다.
2.1 Unbounded data
계속 무한히 증가하는 데이터, 흔히 스트리밍 데이터라고 여겨진다. 그런데, 스트리밍, 혹은 배치(Batch)라는 용어는 특정 데이터를 처리할 때 사용되는 엔진과 관련이 있기 때문에, 조심스럽게 사용해야 한다. 따라서, 이 글에서는 데이터의 종류를 유한성으로 구분하도록 한다. 즉, 무한한 것은 Unbounded data, 유한한 것은 Bounded data라고 정의한다. 우선은 무한한 스트리밍 데이터를 Unbounded data, 유한한 배치 데이터를 Bounded data라고 쉽게 대입해서 생각해도 좋다.
2.2 Unbounded data processing
무한히 흘러드는 Unbounded data를 실시간으로, 그리고 지속적으로 처리하는 방식이다. 일반적인 의미의 스트리밍 엔진뿐만 아니라, 배치 엔진을 반복적으로 사용하는 것도 Unbounded data processing이 될 수 있다. 따라서, 이 글에서 이하 "스트리밍"이라는 용어의 사용은 단순히 Unbounded data를 처리하기 위한 엔진을 의미한다고 가정한다.
3. 스트리밍에 대한 오해 및 새로운 가능성
스트리밍 시스템이 할 수 있는 것과 할 수 없는 것에 대해서 살펴보도록 하자. 이 글의 목적은 잘 디자인된 스트리밍 시스템이 어떤 긍정적인 모습으로 나타날 수 있는지를 강조하는 것이기 때문에, 스트리밍 시스템이 잘 할 수 있는 것들에 중점을 두고 설명을 진행하도록 하겠다.
3.1 Lambda architecture
스트리밍 시스템은 오랜 기간에 걸쳐 부정확하고, 추측에 근거한 결과들을 내놓는다는 부정적인 시선에 시달려왔다. 이러한 선입견은 Lambda Architecture와 같이 상대적으로 정확한 결과들을 도출해내는 배치 시스템들에 의해 더욱 부각되었다. Lambda Architecture의 기본 아이디어는 같은 연산을 수행하는 스트리밍 시스템과 배치 시스템을 함께 사용하는 것이다. 일반적으로, 스트리밍 시스템에서 자주 사용되는 Approximation 알고리즘을 적용하거나, 혹은 스트리밍 시스템 자체가 결과의 정확성에 대한 보장을 해주지 않는 경우 때문에 부정확한 결과가 도출될 수도 있다. 따라서, 이후에 배치 시스템이 따라 실행되면서 정확한 결과를 얻어낼 수 있도록 일조하는 것이다.
결과적으로, 이 아이디어는 굉장히 성공적이었다. 그도 그럴 것이, 스트리밍 엔진은 정확성 측면에서는 부족한 점이 많기 때문이다. 하지만, 람다 시스템은 큰 약점을 가지고 있다. 람다 시스템의 관리자는 두 개의 독립적인 버전의 시스템을 따로 빌드하고 배포해야 하며, 결과적으로 두 개의 파이프라인의 결과를 병합해야 하는 등, 유지보수에 두 배의 노력이 필요하다.
Jay Krep은 이 람다 시스템에 의문을 제기하며, Questioning the Lambda Architecture와 같은 게시글에서 반복성과 관련된 가능성을 제시한다. Kafka처럼 재사용성을 제공하는 스트리밍 상호연결체를 바탕으로 한 시스템을 사용하는, 다시 말해서, 특정 작업을 수행하기 위한 목적으로 잘 디자인된 한 가지 파이프라인을 사용하는 Kappa Architecture를 제안한다.
이 아이디어에 더해 첨언하자면, 사실상 잘 디자인된 스트리밍 시스템은 이론적으로 배치 시스템의 기능적인 상위호환이 될 수 있다고 생각한다. 스트리밍 시스템으로 배치 시스템을 이기려면, 정확성과 시간에 대한 추론이라는 두 마리 토끼를 잡아야 한다.
3.2 Correctness
스트리밍 시스템이 정확성을 갖게 된다면, 배치 시스템과 동등한 지위를 얻게 된다. 정확성 보장의 핵심은 일관된 스토리지 저장소에 있다. 스트리밍 시스템은 전체 시간의 흐름 속에서 끊임 없는 상태(State)의 변화를 기록(Checkpointing)해둘 수 있는 방법이 필요하다. (참고: Jay Krep's Why local state is a fundamental primitive in stream processing) 그리고 시스템 장애와 관련된 측면에서도 시스템의 일관성을 충분히 유지할 수 있도록 잘 디자인되어야 한다. 적어도 정확히 한 번의 처리에 있어서, 강력한 일관성을 보장하는 것이 배치 시스템과의 경쟁에서 승리할 수 있는 토대이다. 처음 Spark 스트리밍이 처음 빅 데이터 필드에 출현했을 때, 이러한 일관성을 보장하도록 스트리밍 시스템들을 인도하는 등대같은 존재가 되었다. 다행스럽게도 이후에 비약적인 발전이 이루어졌다.
3.3 Tools for reasoning about time
스트리밍 시스템에 시간에 대한 추론을 할 수 있는 도구까지 제공된다면, 배치 시스템을 앞서게 된다. 시간상 순차적으로 발생하는 Unbounded data가 네트워크 지연으로 인해 시스템에 전송되면서 순서가 뒤죽박죽이 되기 때문에, 실제 데이터의 발생 시간을 추론해주는 도구는 필수적이다. 이에 대한 심층적인 이해에 앞서, 시간 도메인(Time domains)과 관련된 핵심적인 개념들을 짚고 넘어가도록 하겠다.
4. Event time vs Processing time
이 글에서 사용할 시간 관련 용어로는 Event time과 Processing time이 있다. 이 둘의 정의는 다음과 같다.
Event time: 데이터가 실제로 발생한 시간이상적인 경우는 Event time과 Processing time이 정확히 일치하는 것이다. 즉, 데이터가 발생하자마자 바로 시스템에서 관찰되고, 처리되는 것이다. 하지만, 현실에서는 이러한 경우가 드물다. 데이터, 처리 엔진, 하드웨어의 특성 등에 따라 Event time과 Processing time 사이에는 격차가 발생한다. 이 격차를 Skew라고 하는데, Skew를 유발하는 요인은 대표적으로 세 가지 정도를 들 수 있다.
Processing time: 발생된 데이터가 시스템에 의해 관찰되는 시간
공유된 자원의 제한: 네트워크의 혼잡 및 파티션, 혹은 다용도의 CPU를 사용하는 환경에서의 공유된 CPU 자원결과적으로, Event time과 Processsing time을 그래프로 표현하면 다음과 같이 나타난다.
소프트웨어적인 원인: 분산 시스템에 사용되는 로직과 이로 인해 발생하는 경쟁 상황
데이터 자체의 특성: 보안용 키의 분배, Throughput의 비일관성, 또는 승객들이 비행기 모드로 오프라인에서 휴대폰을 사용하다가 온라인 환경으로 돌아왔을 경우에 발생하는 데이터의 무질서 등

Event time과 Processing time을 매핑하는 것은 정적이지 않기 때문에, 데이터가 실제 발생한 시간이나 순서를 고려해야 하는 경우, 데이터를 분석하는 것은 매우 어려운 작업이 된다. 이러한 문제를 극복하고 무한히 흘러들어오는 Unbounded data를 잘 처리하기 위해서 Windowing과 같은 기법들을 사용하곤 한다. Windowing에 대한 자세한 내용은 다음 글에서 다루도록 하겠다. Windowing의 기본 아이디어는 데이터를 시간상에서 유한한 작은 조각들로 나누어 처리한다는 것이다.
만약 정확성이 요구되는 상황이거나 시계열 데이터를 처리하는 경우, Processing time을 기준으로 Windowing을 하면 문제가 발생한다. Event time과 Processing time의 관계를 정밀하게 분석하여 Event time을 기준으로 Windowing을 해야 한다. 이 과정에서 같은 Window에서 처리되어야 할 Event time 기반의 데이터가 다른 Window에 배정되는 경우 등 여러가지 예외상황들을 함께 고려해주면 된다.
하지만 불행하게도, Event time을 기준으로 Windowing을 하는 것도 마냥 장밋빛 미래를 선사하지는 않는다. Unbounded data를 처리한다는 맥락에서는, 데이터의 무질서와 일관되지 않은 Skew로 인해, 즉, Event time과 Processing time의 완벽한 매핑의 부재로 인해, 특정 Event time X에서 발생한 모든 데이터가 특정 Processing time에 관찰되었다는 식으로 단정짓기가 힘들다. 이를 Completeness의 문제라고 정의한다.
단순히 Unbounded data를 유한한 배치들로 나누어서 결과적으로 Completeness를 보장하는 식의 접근보다는, 복잡한 데이터로 인해 발생하는 불확실성에 대응할 수 있는 도구들을 디자인하는 접근 방식이 요구된다. Completeness의 관점에서 볼 때, 바람직한 시스템은 새로운 데이터가 들어올 경우, 오래된 데이터를 철회하거나 갱신하는 과정을 스스로 수행할 수 있어야 한다. 이러한 시스템에 대해 상세히 논의하기 전 이론적인 초석을 다지기 위하여, 다음 글에서는 데이터를 처리하는 여러가지 기법들에 대해서 자세히 살펴보도록 하겠다.
5. References
https://www.oreilly.com/ideas/the-world-beyond-batch-streaming-101
https://www.oreilly.com/ideas/the-world-beyond-batch-streaming-102






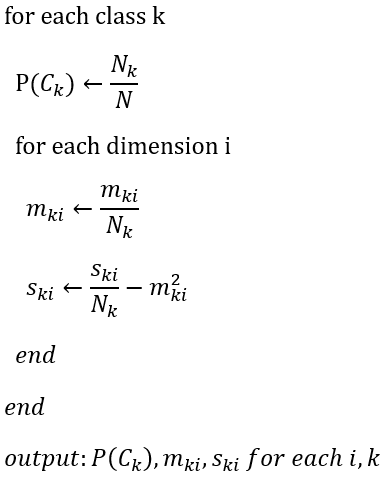











![[C/C++] 고정 소수점의 모든 것 (All about Fixed Point)](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjIsNbQ5x9v-Z-WFogOWc-Lns6r9bJLAy9DBCVnl33dXsyXViNgjXrSvmnXzfOeL8m5Wb5VqImEKI0L-B9ZXzc2XmgWpmKCVFv87svXDsHG5WO_4sqVg-y2sRtuqbStxGf2HQ28wBdKIKBV/w72-h72-p-k-no-nu/%25EA%25B3%25A0%25EC%25A0%2595+%25EC%2586%258C%25EC%2588%2598%25EC%25A0%2590+%25EA%25B7%25B8%25EB%25A6%25BC.PNG)


![[R] 다중 회귀 분석 (Multiple Regression Analysis)](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEgcv_-dAHO3EpXA84aAoidUMHJU6rKRsfYflGImKb829FBTDDyw01WftJ-PZD_UakTKM4u5KeubMIaau5zkwBtuYXPqdkpbvFOI_Tv3FFjKFYxkCaKknGFyclAUQrJlzyGwOtLzvotXhTFT/w72-h72-p-k-no-nu/%25ED%259A%258C%25EA%25B7%2580+%25EB%25B6%2584%25EC%2584%259D.PNG)
