세그먼트 트리(Segment Tree)는 배열처럼 데이터가 일렬로 나열되어 있을 때, 특정 구간의 합, 또는 특정 구간에서 가장 큰 수 등 구간의 정보를 효율적으로 얻어내기 위해 설계된 자료구조이다. 세그먼트 트리에 대해 자세히 알아보고, 구현 방법을 살펴보도록 하자.
2. 세그먼트 트리의 기본 개념
(1) 기본 구조
세그먼트 트리는 이진 트리(Binary Tree)로서, 각 노드는 특정 구간의 정보를 지니고 있고, 부모 노드가 자식 노드의 구간 범위 전체를 포괄하는 것을 기본 원칙으로 한다. 예를 들어, 구간 합의 정보를 저장한 세그먼트 트리의 노드1과 노드2가 각각 1 ~ 4번 데이터의 구간 합, 5 ~ 8번 데이터의 구간 합을 지니고 있다면, 노드1과 2의 부모 노드는 1 ~ 8번 데이터의 구간 합을 지니게 된다.
세그먼트 트리의 가장 최상단 루트 노드(Root Node)는 전체 구간의 정보를 지니며, 가장 최하단의 리프 노드(Leaf Node)들은 크기가 1인 범위, 즉, 각 인덱스의 데이터 하나를 지닌다. 배열로 따지면 배열의 각 요소들이 하나의 리프 노드가 되는 것이다.
(2) 연산
세그먼트 트리의 대표적인 연산으로는 데이터 갱신(Update)과 질의(Query)가 있다.
Update(Index, Data)데이터 갱신(Update)은 새로운 데이터의 추가, 기존 데이터의 수정 및 삭제를 모두 포함한다. 기본적으로 데이터의 위치인 인덱스(Index)와 실제 데이터가 인자로 제공된다. 이를 바탕으로 특정 인덱스 위치에 있는 데이터를 갱신하는 작업을 수행한다.
Query(From, To)
질의(Query)는 구간의 정보를 탐색하여 사용자에게 반환해주는 작업을 수행한다. 기본적으로 질의하고자 하는 구간의 시작 인덱스와 끝 인덱스가 인자로 제공된다. 예를 들어, 구간 합 세그먼트 트리에 Query(1, 4)를 수행할 경우, 1번, 2번, 3번, 4번 데이터의 합이 반환된다.
3. 구현 방법
세그먼트 트리는 완전 이진 트리(Complete Binary Tree)이다. 위키피디아에 의하면, 완전 이진 트리의 정의는 다음과 같다.
(1) 마지막 레벨을 제외하고 모든 레벨이 완전히 채워져 있으며, 마지막 레벨의 모든 노드는 가능한 한 가장 왼쪽에 있는 트리이는 세그먼트 트리의 데이터들이 각각 특정 인덱스를 가지고 순차적으로 나열되어 있다는 가정과, 상위 노드가 하위 노드들의 구간의 범위를 모두 포함한다는 조건때문에 성립한다. 따라서, 루트 노드를 1번으로 시작하여 각 레벨의 노드들을 순차적으로 나열하면 빈 공간 없이 모든 노드가 일렬로 배치되기 때문에, 기본적으로 배열을 사용하여 세그먼트 트리를 구현한다.
(2) 가장 오른쪽의 잎 노드가 (아마도 모두) 제거된 포화 이진 트리(Perfect Binary Tree)
세그먼트 트리를 구현하는 방법에는 크게 두 가지가 있다. 하나는 Bottom-up 방식이고, 두 번째는 Top-down 방식이다. Bottom-up 방식은 단순 반복문을 이용하여 최하단의 리프 노드부터 상향하며 데이터를 갱신하거나 질의하는 방식을 뜻하며, Top-down 방식은 반대로 최상단의 루트 노드부터 시작하여 재귀 함수를 통해 하향하며 데이터를 갱신하거나 질의하는 방식을 뜻한다.
Bottom-up 방식의 경우, 배열과 단순 반복문을 사용하기 때문에 구현도 상대적으로 쉽고, 일반적으로 재귀 함수를 사용하는 Top-down 방식보다 성능 면에서도 뛰어나기 때문에 간단한 문제에서는 Bottom-up 방식을 사용하는 것이 유리하다. 반대로, Top-down 방식의 경우에는 확장성이 뛰어나다는 장점 때문에 복잡한 문제에서는 Top-down 방식을 사용하는 것이 유리한 경우가 종종 있다.
예를 들어, 단순히 특정 인덱스에 있는 하나의 데이터를 갱신하는 것이 아니라, 특정 구간 전체의 데이터에 변화를 주어 트리 내부의 많은 노드에 수정 사항이 발생하는 경우에는, Top-down 방식에 Lazy Propagation과 같은 심화적인 기법을 추가하여 효율적으로 문제를 해결할 수 있다. 반면, Bottom-up 방식은 Lazy Propagation을 적용할 수 없기 때문에 구간의 정보를 한꺼번에 갱신하는 것에는 한계가 있다.
그렇다면, Bottom-up 방식과 Top-down 방식을 어떤식으로 구현할 수 있는지 각각 예제와 함께 살펴보도록 하자. 예제는 구간 합 세그먼트 트리를 바탕으로 하며, C/C++를 기준으로 설명하도록 하겠다.
3-1. Bottom-up 방식
Bottom-up 방식은 모든 연산이 가장 최하단의 리프 노드부터 시작하여 루트 노드까지 위쪽으로 상승하며 이루어진다. 트리 구조를 만드는 법, 데이터를 갱신하는 법, 데이터를 질의하는 법에 대해 알아보자.
(1) 트리 구조 만들기 - BuildTree
순차적으로 저장되어 있는 N개의 데이터는 세그먼트 트리의 가장 최하단의 리프 노드들에 각각 저장된다. 앞서 언급했듯이, 세그먼트 트리는 완전 이진 트리 구조이기 때문에, 최하단 레벨의 노드의 최대 개수는 2의 거듭제곱이고, 이를 Capacity라고 했을 때 리프 노드들을 제외한 모든 노드들의 개수는 Capacity - 1개가 된다. Binary Heap과 유사하게 노드의 상하관계를 배열의 인덱스로 효율적으로 나타내기 위하여, 0번 인덱스는 사용하지 않고 루트 노드를 1번 인덱스에 두고 트리를 만들기 때문에 전체 세그먼트 트리는 Capacity * 2 크기의 배열로 표현할 수 있다. 따라서, N보다 큰 2의 제곱수 중에서 가장 작은 수를 찾아서 Capacity로 설정하고, Capacity * 2 크기의 배열을 생성하도록 하자.
for(Capacity = 1; Capacity < N; Capacity *= 2);예를 들어, N = 6일 경우 Capacity는 8이 되고, 이것이 최하단 레벨, 즉, 리프 노드의 개수가 된다. 그리고 최하단 레벨을 제외한 노드들의 개수는 7개이다.
int* tree = new int[Capacity * 2];

int data[] = {1, 2, 3, 4, 5, 6};그 다음은 상위 노드들의 정보를 갱신할 차례이다. 배열의 인덱스 i에 특정 노드가 있을 때, 해당 노드의 좌측 하위 노드는 인덱스 i * 2에 위치하고, 우측 하위 노드는 인덱스 i * 2 + 1에 위치하게 된다. 이 성질을 바탕으로 최하위 레벨의 바로 윗 레벨부터 시작하여, 최상단의 루트 노드까지 거슬러 올라가면서 하위 노드의 정보를 상위 노드에 포함하는 작업을 한다. 예를 들어, 인덱스 1 ~ 6 범위의 데이터의 합을 나타내는 루트 노드는, 1 ~ 4 범위의 데이터의 합을 가진 좌측 하위 노드와 5 ~ 6 범위의 데이터의 합을 가진 우측 하위 노드의 값을 더함으로써 1 ~ 6 범위의 데이터의 합을 구하게 된다.
cnt = 0;
for(i = Capacity; i < Capacity + N; i++) tree[i] = data[cnt++];
for(i = Capacity + N; i < capacity * 2; i++) tree[i] = 0;
void BuildTree(int N, int* data) {이렇게 하면, 기본적으로 N개의 초기 데이터를 포함한 세그먼트 트리가 완성된다.
int i, cnt = 0;
for(Capacity = 1; Capacity < N; Capacity *= 2);
tree = (int*)malloc(sizeof(int) * Capacity * 2);
for(i = Capacity; i < Capacity + N; i++) tree[i] = data[cnt++];
for(i = Capacity + N; i < Capacity * 2; i++) tree[i] = 0;
for(i = Capacity - 1; i > 0; i--) tree[i] = tree[i * 2] + tree[i * 2 + 1];
}
(2) 데이터 삽입, 수정, 삭제하기 - Update
특정 인덱스 i 위치에 데이터를 삽입하거나, 해당 위치의 데이터를 수정하거나 삭제하는 것은 하나의 함수로 동일하게 처리할 수 있다. 인자로 주어진 인덱스 i에 있는 데이터를 갱신한 다음, 바로 상위 노드부터 시작하여 루트 노드까지 거꾸로 올라가면서 인덱스 i를 포함하는 구간의 정보들을 갱신하면 된다. 이때, 초기 N개의 데이터들은 인덱스 Capacity부터 시작한다는 점을 상기해야 한다. 즉, 인덱스 Capacity + i에 있는 값을 갱신하고, 상위 노드로 올라가면서 구간 정보들을 갱신하면 된다.
void Update(int i, int data) {이렇게 하면, N개 데이터의 갱신에 대해 O(NlogN)의 시간복잡도를 가진다.
int k = Capacity + i;
tree[it] = data;
for(it = it / 2; it > 0; it--) tree[it] = tree[it * 2] + tree[it * 2 + 1];
}
(3) 데이터 질의하기 - Query
구간의 시작 점과 끝 점이 인자로 주어졌을 때, 해당 구간의 정보를 얻기 위해서는 해당 구간에 포함된 모든 서브 트리(Subtree)들의 정보를 합하는 과정이 필요하다. 예를 들어, 3 ~ 4 범위의 구간 합을 얻고자 한다면, 단순히 3 ~ 4 범위를 커버하는 상위 노드의 값 하나(7)를 반환해주면 된다. 그러나, 2 ~ 5 범위의 구간 합을 얻고자 한다면, 3 ~ 4 범위뿐만 아니라 2 ~ 2와 5 ~ 5 범위의 값도 최종 결과에 합산해주어야 한다.
예제와 함께 살펴보도록 하자. 1 ~ 6의 데이터가 담긴 구간 합 세그먼트 트리에서 2 ~ 5 범위의 구간 합을 구한다고 가정한다. Query 함수의 인자로는 범위의 양 끝 인덱스 2, 5가 주어진다. 양쪽 끝 인덱스를 가리키기 위한 커서 두 개를 만들어 이를 각각 L(left), R(right)라고 하자. 그렇다면 초기 상태는 L = 2, R = 5가 된다.
Query(L, R)만약 특정 인덱스 i에 대하여 i % 2 = 1일 경우, 인덱스 i의 노드는 우측 자식 노드임을 뜻하며, i % 2 = 0인 경우는 반대로 좌측 자식 노드임을 뜻한다. (완전 이진 트리의 성질 때문에 인덱스 i에 위치한 특정 노드의 자식 노드의 개수는 항상 0 또는 2개이고, 좌측 자식 노드는 i * 2, 우측 자식 노드는 i * 2 + 1에 위치한다는 점을 상기하자.) 이때, 두 가지 주의할 점이 있다.
L이 우측 자식 노드라는 뜻은, L 바로 왼쪽의 노드는 범위에 포함되지 않는다는 뜻이다. 즉, 상위 노드의 정보가 필요하지 않음을 의미한다. 상위 노드는 L 바로 왼쪽의 노드의 정보도 포함하기 때문이다.이 두 가지 경우에 대해서는 더 이상 상위 노드의 정보를 탐색하지 않고, 바로 L과 R에 위치한 노드의 값을 최종 값에 합산한 뒤에 진행한다. L은 한 칸 우측으로 진행(L++)하면 되고, R은 한 칸 좌측(R--)으로 진행하면 된다. 즉, 2와 5의 값을 이미 최종 값에 반영했으므로, 다시 Query(3, 4)를 호출하는 것과 동일한 효과를 얻게 된다.
마찬가지로, R이 좌측 자식 노드라는 뜻은 R 바로 오른쪽의 노드가 범위에 포함되지 않는다는 뜻이다. 이 경우에도 상위 노드의 정보는 불필요하다.
그렇다면, 앞선 두 가지 경우에 해당하지 않는 경우는 어떨까? 쉽게 예상할 수 있듯이, L과 R의 바로 옆 Sibling이 구하고자 하는 범위에 함께 포함되는 것이다. 이는 곧, 상위 노드의 정보로 대치할 수 있다는 의미이다. 따라서, 인덱스 L과 R을 2로 나누어 상위 노드를 참조하게 한다.
L < R인 동안 계속 이 작업을 반복하다보면, 구하고자 하는 범위의 모든 값들이 포함된다. 단, 마지막 L = R인 경우, 해당하는 노드의 값을 최종 값에 합산해주기만 하면 Query에 대한 답을 구할 수 있다.
int Query(int L, int R) {
int ret = 0;
L += Capacity;
R += Capacity;
for(; L < R; L /= 2, R /= 2) {
if(L % 2) ret += tree[L++];
if(!(R % 2)) ret += tree[R--];
}
if(L == R) ret += tree[L];
return ret;
}
3-2. Top-down 방식
Bottom-up 방식과는 반대로, 모든 연산은 루트 노드에서부터 시작하면서 아래쪽으로 하강하면서 이루어진다.

(1) 트리 구조 만들기 - BuildTree
Bottom-up 방식과 마찬가지로 데이터의 수 N보다 큰 2^n 중 최소값을 찾아 Capacity로 설정한다. 그 다음, (2)에서 다룰 Update 함수를 N개의 데이터에 대해 수행하면 된다.
(2) 데이터 삽입, 수정, 삭제하기 - Update
기본적으로 5개의 인자가 필요하다. 노드를 순회하기 위한 배열 상의 인덱스 n, 그리고 인덱스 n에 위치한 노드가 커버하는 구간을 나타내기 위한 시작 인덱스 s와 끝 인덱스 e, 그리고 N개의 데이터를 배열에 저장했다고 가정했을 때의 인덱스 i, 그리고 저장할 데이터 data이다.
Update(n, s, e, i, data)이 인자들의 정보를 트리 노드로 표현하면 다음과 같다.
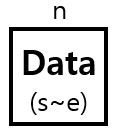
우선, s와 e의 중간지점을 구해 변수 m에 저장해두고, 이를 기준으로 양쪽 서브 트리 중 인덱스 i를 포함한 구간으로 분기한다. 재귀적으로 다음과 같이 함수를 호출하면 된다.
m = (s + e) / 2;이러한 방식으로 서브 트리를 타고 내려가다 보면, s = e인 경우, 즉, 구간에 포함된 노드의 수가 1개인 리프 노드에 도달하게 되는데, 이때 해당 위치에 data를 삽입하면 된다.
if(i <= m) Update(n * 2, s, m, i, data);
else Update(n * 2 + 1, m + 1, i, data);
리프 노드에 데이터를 삽입하고 나면, 재귀 호출된 함수가 종료되면서 다시 거꾸로 상위 노드 쪽으로 이동하게 되는데, 이때 새로 업데이트된 하위 노드의 정보를 담아야 하므로, 양쪽 하위 노드의 값을 더하여 해당 상위 노드에 저장하도록 한다. 이 과정을 포함한 전체 코드는 다음과 같다.
void Update(int n, int s, int e, int i, int data) {
if(s == e) tree[n] = data;
else {
int m = (s + e) / 2;
if(i <= m) Update(n * 2, s, m, i, data);
else Update(n * 2 + 1, m + 1, e, i, data);
tree[n] = tree[n * 2] + tree[n * 2 + 1];
}
}
(3) 데이터 질의하기 - Query
인자 5개가 필요하다. (2)에서 살펴본 n, s, e는 동일하고, 질의하고자 하는 구간의 시작 인덱스를 L, 끝 인덱스를 R이라고 정의한다.
Query(n, s, e, L, R)
서브 트리를 순회하는 방식은 (2)처럼 변수 m 값에 s와 e의 중간 값을 저장하고 이를 중심으로 양쪽으로 분기하는 방식을 따른다. 단, 구간의 합을 구해야 하는 것이기 때문에, 구간의 정보들을 모으기 위하여 재귀적으로 양쪽 서브 트리의 값을 합쳐준다.
return Query(n * 2, s, m, L, R) + Query(n * 2 + 1, m + 1, e, L, R);
단, 이때 L과 R 구간에 포함되는 서브 트리의 정보만 반영을 해야 한다. 이를 관련해서 다음과 같이 세 가지 경우를 생각해볼 수 있다.
(1) L ~ R 구간에서 아예 벗어난 서브 트리
-> 반환 값에서 제외한다.
(2) L ~ R 구간과 s ~ e 구간이 일부 겹치는 서브 트리
-> L ~ R 구간에 포함되지 않는 정보를 제외하기 위해 재귀적으로 Query를 호출한다.
(3) L ~ R 구간에 완전히 포함되는 서브 트리
-> 해당 서브 트리의 루트 노드(인덱스 n에 위치한 노드)의 값을 반환한다.
(2)의 경우는, 위에서 언급했듯이 return 값으로 반환을 하는 default 경우에 해당하므로 (1)과 (3) 조건만 고려해주면 된다. 이를 코드로 구현하면 다음과 같다.
int Query(int n, int s, int e, int L, int R) {
if(R < s || e < L) return 0;
if(L <= s && e <= R) return tree[n];
int m = (s + e) / 2;
return Query(n * 2, s, m, L, R) + Query(n * 2 + 1, m + 1, e, L, R);
}
4. 심화: Lazy Propagation을 통한 데이터 다중 갱신
2에서 언급했듯이, Top-down 방식으로 세그먼트를 구현할 경우 Lazy Propagation 기법을 통해 구간의 데이터를 한꺼번에 갱신하는 것이 가능하다. Lazy Propagation이라는 것은 말그대로 게으르게 전파하는 방식이다. 즉, 어떤 값을 갱신해야 할 때, 해당 값이 당장 필요한 값이 아니라면, 나중에 필요한 시점이 올 때까지 갱신을 미루는 것이다.
우선, Lazy Propagation을 구현하기 위해서는 세그먼트 트리의 특정 노드가 갱신을 미루고 있는지를 확인하기 위한 lazy 배열이 필요하다. 세그먼트 트리를 구성하는 배열의 크기와 동일하게 만들면 된다. 인덱스 n에 위치한 노드에 대해 lazy[n] > 0일 경우, 해당 노드가 갱신을 미루고 있다는 의미이고, lazy[n] = 0일 경우는 이미 최신 정보가 반영되었음을 의미한다.
그리고 특정 노드 n이 미루고 있던 갱신을 진행하고 n의 하위 노드의 lazy 값을 변경해주는 Propagate 함수를 구현해야 한다. 즉, 노드 n의 정보만 실제로 갱신하고, 하위 노드들은 갱신을 뒤로 미루도록 하는 것이다.
void Propagate(int n, int s, int e) {
if(lazy[n]) {
if(s != e) {
lazy[n * 2] += lazy[n];
lazy[n * 2 + 1] += lazy[n];
}
tree[n] += (e - s + 1) * lazy[n];
lazy[n] = 0;
}
}
노드 n이 리프 노드가 아닌 경우(s != e)에는 하위 노드가 없으므로, 노드 n의 정보만 갱신하고 함수를 종료하도록 구현하였다. 하위 노드가 있는 경우에는 현재 노드 n이 갱신을 미루고 있던 값(lazy[n])을 하위 노드에 전파해준다. 그러면 하위 노드가 해당 값을 나중에 필요할 때 자신의 구간 보에 갱신할 것이다.
노드 n의 정보를 갱신할 때는, 노드 n이 커버하는 리프 노드의 개수(e - s + 1)에 갱신을 미루고 있던 값(lazy[n])을 곱한 값을 더해준다. 그리고 나서 lazy[n]에 0을 대입하여 최신 정보가 반영되었음을 표시해준다.
이 Propagate 함수는 갱신이 필요한 시점마다 호출해주면 된다. 대표적인 예로, 사용자가 Query 함수를 수행할 경우, L ~ R 구간에 포함되는 노드들은 모두 최신 정보로 갱신이 필요하다. 따라서 Query 함수의 첫 줄에 Propagate 함수를 호출해주면 된다.
이제 구간 정보를 동시에 갱신할 수 있는 준비물이 모두 마련되었다. Propagate 함수를 활용해 UpdateAll 함수를 구현해보자. 이 함수는 Top-down 방식의 Query 함수와 유사한 인자들을 받는다. Query 함수와 동일한 인자 다섯 개를 기본으로 하며, 이와 별개로 구간에 일괄적으로 반영할 변화량(change)을 갖는다. (cf. Update 함수는 갱신할 값 하나(data)를 인자로 받음)
UpdateAll(n, s, e, L, R, change)
Update를 하는 방식은 Query 함수와 유사하게 진행된다. 노드 n이 주어진 구간 L과 R에 포함되는 서브 트리의 루트 노드일 경우, lazy[n]의 값에 change를 더하여 갱신이 필요함을 명시해준 뒤, Propagate 함수를 호출하여 노드 n의 값을 갱신하고 자식 노드들에게 갱신이 필요함을 알린다.
노드 n이 루트 노드인 서브 트리가 L과 R에 완벽히 포함되지 않는 경우, Query 함수와 동일하게 재귀적으로 UpdateAll 함수를 호출한다. 그리고 함수 끝에는 하위 노드들의 정보를 상위 노드에 반영해주는 코드를 추가한다.
5. Source Code
Bottom-up: https://github.com/arkainoh/algorithms/blob/master/c/SegmentTree.c
Top-down: https://github.com/arkainoh/algorithms/blob/master/c/AdvancedSegmentTree.c
노드 n이 루트 노드인 서브 트리가 L과 R에 완벽히 포함되지 않는 경우, Query 함수와 동일하게 재귀적으로 UpdateAll 함수를 호출한다. 그리고 함수 끝에는 하위 노드들의 정보를 상위 노드에 반영해주는 코드를 추가한다.
void updateAll(int n, int s, int e, int L, int R, int change) {
propagate(n, s, e);
if(R < s || e < L) return;
if(L <= s && e <= R) {
lazy[n] += change;
propagate(n, s, e);
return;
}
int m = (s + e) / 2;
updateAll(n * 2, s, m, L, R, change);
updateAll(n * 2 + 1, m + 1, e, L, R, change);
tree[n] = tree[n * 2] + tree[n * 2 + 1];
}
5. Source Code
Bottom-up: https://github.com/arkainoh/algorithms/blob/master/c/SegmentTree.c
Top-down: https://github.com/arkainoh/algorithms/blob/master/c/AdvancedSegmentTree.c
![[Algorithm] 세그먼트 트리 (Segment Tree)](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEigeO_X2rXzmvaNIV-CsHa-OUFoNfcQ2wa2EmN57d63L_j7HqSz2Kk78PBVleAveAB_D5byRPIfK6QKtQ1KH57ux2VLW5meYi9S5O8Gc-sy_bAU7NxURYTO4nzmWeAYIW6Hd1g9xmGVhMPa/s72-c/%25EC%2584%25B8%25EA%25B7%25B8%25EB%25A8%25BC%25ED%258A%25B8+%25ED%258A%25B8%25EB%25A6%25AC.JPG)
![[C/C++] 고정 소수점의 모든 것 (All about Fixed Point)](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjIsNbQ5x9v-Z-WFogOWc-Lns6r9bJLAy9DBCVnl33dXsyXViNgjXrSvmnXzfOeL8m5Wb5VqImEKI0L-B9ZXzc2XmgWpmKCVFv87svXDsHG5WO_4sqVg-y2sRtuqbStxGf2HQ28wBdKIKBV/w72-h72-p-k-no-nu/%25EA%25B3%25A0%25EC%25A0%2595+%25EC%2586%258C%25EC%2588%2598%25EC%25A0%2590+%25EA%25B7%25B8%25EB%25A6%25BC.PNG)


![[R] 다중 회귀 분석 (Multiple Regression Analysis)](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEgcv_-dAHO3EpXA84aAoidUMHJU6rKRsfYflGImKb829FBTDDyw01WftJ-PZD_UakTKM4u5KeubMIaau5zkwBtuYXPqdkpbvFOI_Tv3FFjKFYxkCaKknGFyclAUQrJlzyGwOtLzvotXhTFT/w72-h72-p-k-no-nu/%25ED%259A%258C%25EA%25B7%2580+%25EB%25B6%2584%25EC%2584%259D.PNG)

세세한 부분까지 설명해주셔서 너무 이해가 잘 됐습니다. 감사드려요
답글삭제bottom up도 lazy propagation이 가능합니다! https://codeforces.com/blog/entry/18051
답글삭제